A 2025 UpGuard study of 500 security leaders and 1,000 employees found that 81% of workers and 88% of security leaders admit using unapproved AI tools. The same workforce that is supposed to govern AI is, statistically, also the one operating outside the rules. This is the starting condition almost every organization is in when it sits down to build its first AI inventory: the systems exist, the use is widespread, and almost no one in the building can produce a complete list.
Regulators no longer treat that as acceptable. Under ISO/IEC 42001, the NIST AI Risk Management Framework, and the EU AI Act, an inventory of AI systems is the prerequisite for nearly every other control. You cannot perform a risk assessment, assign accountability, or claim “reasonable care” for a system you have not catalogued. This guide walks through how to build that inventory from scratch, including how to find what you do not yet know exists.
What an AI Inventory Actually Is (And What It Is Not)
An AI inventory is a maintained register of every AI system your organization develops, deploys, procures, or embeds into its products, along with the metadata needed to govern each one. It sits at the same layer of your governance stack as a CMDB or data inventory, but it is purpose-built for the unique attributes of AI: model lineage, training data provenance, intended use, risk classification, and human oversight assignments.
It is not a spreadsheet of vendors. It is not the output of a single procurement scan. And it is not a one-time exercise the rate at which AI capabilities are added to existing SaaS tools (often through silent feature releases) makes the inventory a living artefact.
The distinction matters because most organizations confuse “we have a list of approved vendors” with “we have an AI inventory.” The first is a procurement record. The second is a governance instrument. Procurement records do not capture an analytics platform that quietly added a generative AI assistant in its last release, a marketing team’s API key into Anthropic, or an internal Python script using a fine-tuned model on a developer’s laptop. A real inventory does.
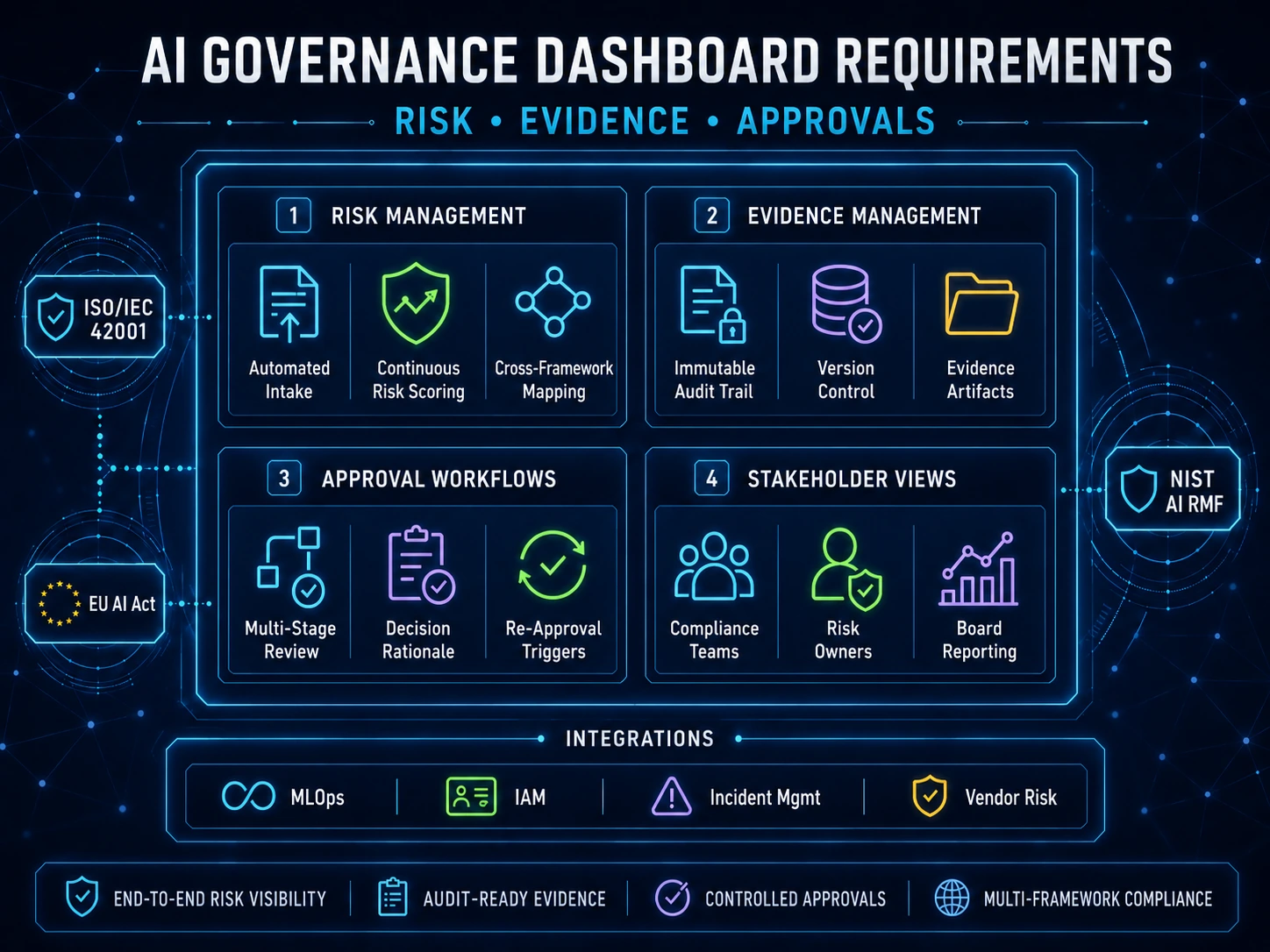
Under the NIST AI RMF, this register supports the Govern 1.6 function, which expects mechanisms in place to inventory AI systems and resource them according to organizational risk priorities. ISO/IEC 42001 calls for the same capability through its resource documentation requirements in Annex B (B.4.2 through B.4.6, covering data, tooling, system, and human resources). Both frameworks treat inventory as foundational rather than optional.
Why Building One Now Is Non-Negotiable
The window for “we’ll get to it later” closed in 2025. Three pressures converged.
First, regulation. The EU AI Act’s high-risk obligations bind any provider whose system touches an EU resident, regardless of where the provider is based. In the United States, Colorado’s AI Act gives organizations a rebuttable presumption of “reasonable care” if they align with NIST AI RMF or ISO/IEC 42001. Both starting points require an inventory. Texas, California, and a growing list of state-level frameworks are following similar patterns, and federal agency procurement increasingly requires AI disclosure as a condition of contract.
Second, scale. Federal Reserve research released in April 2026 found that work-related generative AI adoption among US individuals stood at roughly 41% as of November 2025, with the strongest growth occurring in the most recent quarter measured. Enterprise AI adoption is doubling roughly every 12 to 18 months. Each month an inventory is delayed adds dozens to hundreds of systems that will need to be retrospectively catalogued.
Third, breach economics. According to data referenced in the SQ Magazine 2026 shadow AI report, the average cost of a shadow AI data breach has reached $4.2 million, and roughly 76% of shadow AI tools fail SOC 2 standards. Insurance carriers are now writing AI exclusions into cyber policies for organizations without demonstrated governance — and demonstrated governance starts with the register.
The trend is clear: the cost of building an inventory rises every quarter you delay it, while the cost of not having one is increasingly priced into regulatory penalties, breach exposure, and lost contracts.
What to Capture: The Metadata Schema
Before you start discovery, define the schema. The most common mistake teams make is collecting AI systems first and trying to figure out what data to store about them later. By the time you finish discovery, you will have inconsistent records, missing fields, and no way to filter for the systems that actually need governance attention.
A defensible AI inventory captures the following per system:
| Field | Purpose | Source / Owner |
| System ID & name | Unique identifier across the organization | Inventory owner |
| Description & intended use | What the system does and what decisions it informs | Business owner |
| Lifecycle stage | Concept, development, production, retired | Technical owner |
| Build vs buy vs embedded | Determines downstream documentation duties | Procurement / engineering |
| Vendor & contract reference | Links to data processing agreements and DPAs | Procurement / legal |
| Model details | Foundation model, fine-tuning, version, provider | Engineering |
| Training data sources | Provenance, licensing, sensitive data flags | Data governance |
| Inputs & outputs | Data classes consumed and produced | Data governance |
| Users & access scope | Internal teams, external customers, public | Business owner |
| Decision impact | Informs / recommends / automates a decision | Risk / compliance |
| Risk classification | Mapped to EU AI Act and internal tiers | Risk / compliance |
| Human oversight | Who reviews, when, and against what criteria | Business owner |
| Performance metrics & monitoring | Drift, bias, accuracy thresholds | Engineering / MRM |
| Incidents & known limitations | Logged failures, scope exclusions | Risk / compliance |
| Accountable executive | Single named role accountable for outcomes | Governance |
| Last reviewed date | Triggers periodic recertification | Governance |
A few of these fields require deliberate attention. Decision impact is the single most useful classifier — a system that automates a hiring decision sits in a different governance tier than one that drafts marketing copy, even if both use the same underlying model. Accountable executive must be a named individual, not a team or a function; ambiguity here is the most reliable predictor of governance failure during an audit.
For systems that produce models you ship to others (whether to customers or to other internal teams), append an AI Bill of Materials (AIBOM) a structured record of the model components, training datasets, dependencies, and known constraints. This is becoming the AI equivalent of an SBOM and will be a procurement requirement for federal contracts in the near term.
How to Discover What You Don’t Know You Have
Discovery is where most AI inventory projects fail. The teams who own the project know about the AI they built. They do not know about the AI someone else bought, the AI that was added to a tool they already had, or the AI that an employee pasted a customer list into yesterday afternoon.
You need a multi-source approach because no single signal catches everything.
Procurement and finance records. Pull a 24-month export of vendor payments and SaaS subscriptions. Filter for known AI vendors (OpenAI, Anthropic, Google AI, AWS Bedrock, Azure OpenAI, Cohere, Mistral, Perplexity, Hugging Face) and their resellers. Then filter for any line item containing the strings “AI,” “GPT,” “ML,” “intelligence,” “copilot,” “assistant,” or “automation.” Expect false positives. The point is to surface candidates for review, not to make purchase decisions.
Identity and SSO logs. Your SSO provider (Okta, Entra ID, Google Workspace) holds a complete record of every SaaS application employees authenticate into. Pull the application catalogue, sorted by user count. Cross-reference against your procurement list to find applications that are in active use but have no procurement record — a strong shadow AI signal.
Network and proxy telemetry. Secure web gateways, CASBs, and DNS logs reveal traffic to AI domains even when no account is provisioned. Menlo Security observed a 50% increase in enterprise web traffic to generative AI sites in a single year, with 80% of access happening through browsers. That traffic leaves a record. Look specifically for traffic to consumer AI endpoints from corporate devices.
Code and repository scans. Run a scan across your code repositories for API calls to AI endpoints, imports of AI SDKs, and references to MCP servers. Tools in the AI software supply chain security category (Checkmarx, Snyk’s AI scanning, GitHub’s secret scanning extensions) automate this. A manual grep for openai, anthropic, langchain, and huggingface across repos will catch most of what an automated tool would, if budget is a constraint.
Browser extension audits. Browser-based AI assistants are the largest single category of shadow AI in enterprise environments and the hardest to detect from the network because the AI inference happens server-side at the extension’s domain. Pull installed extension lists from your endpoint management tool.
Direct surveys, with structure. Send a short, structured survey to each business unit. Two questions outperform a 20-question form: (1) List every tool you use that generates text, images, code, audio, video, predictions, recommendations, or summaries. (2) List every workflow where you paste data into an AI tool, even occasionally. Frame it as discovery, not enforcement. Respondents who feel they will be punished for honest answers will under-report; the Reco 2025 report found that even with formal training, 40% of employees continue using unapproved tools daily, which means survey-only discovery is structurally incomplete.
Embedded AI feature audits. This is the category most inventories miss entirely. Salesforce, HubSpot, Zoom, Notion, Slack, Microsoft 365, Google Workspace, Adobe Creative Cloud, and dozens of other tools your organization already pays for have added AI features in the past 18 months. Many were enabled by default. Maintain a watchlist of your top 30 SaaS vendors and review their release notes quarterly for new AI capabilities.
The combined output of these sources is your raw discovery dataset. Expect duplicates, false positives, and entries that need clarification. Plan for at least one full-time equivalent of effort over four to six weeks for an organization of 1,000 employees, scaling roughly linearly from there.
A 14-Day Discovery Sprint That Actually Works
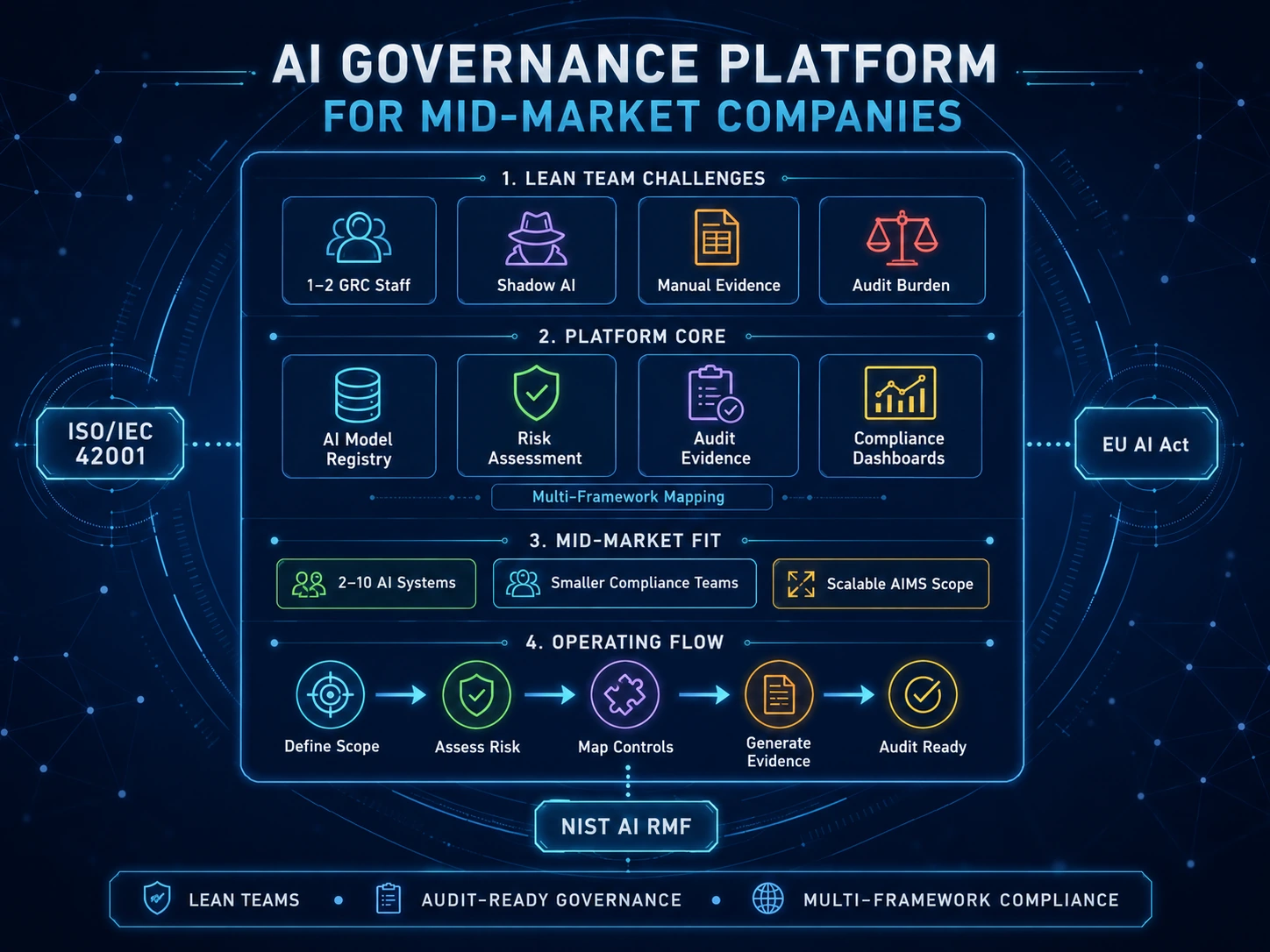
For organizations starting from zero, a structured sprint gets you to a defensible first-pass inventory faster than an open-ended project. The sprint is not the finish line — it is the credible starting point that lets governance work begin in parallel with refinement.
Days 1–2: Frame and authorize. Get written sponsorship from a senior executive (CIO, CISO, Chief Risk Officer, or General Counsel, depending on your structure). Define the inventory scope: AI systems used by employees, AI systems embedded in products you ship, AI systems used by vendors processing your data. Lock the metadata schema. Stand up a single shared store — a structured database, a governance platform, or at minimum a well-designed spreadsheet with locked columns.
Days 3–5: Run the automated pulls. Procurement extracts, SSO application catalogues, network and proxy logs, repository scans, endpoint extension lists. Run them all in parallel. Assign each to its owning team with a clear delivery date. The deliverable from each is a list of candidate systems, not a final inventory.
Days 6–8: Send the structured survey. One survey per business unit, with the two-question structure above. Set a hard deadline of 72 hours. Follow up directly with non-responders — this is where executive sponsorship matters.
Days 9–11: Triage and de-duplicate. Merge the discovery sources. Resolve duplicates. For each candidate, identify the business owner and assign them as the data steward for that record. Create a “review queue” of ambiguous entries — items that may or may not qualify as AI systems under your definition.
Days 12–13: Risk-classify and prioritize. Run a rapid first-pass risk classification on the merged inventory. Use a simple tiering scheme: high (automates or significantly informs decisions affecting individuals), medium (substantively assists internal work with limited external impact), low (productivity tools with minimal data sensitivity). The point is to identify the 10 to 30 systems that need immediate governance attention, not to perfect the classification.
Day 14: Publish the v1 inventory and the gap list. Distribute the inventory to executive sponsors with a clear summary: total systems found, systems by risk tier, systems lacking ownership, systems flagged for immediate review, known coverage gaps. The gap list matters as much as the inventory itself — it acknowledges what you have not yet found and sets the agenda for ongoing discovery.
The output of this sprint is not complete. It is defensible, which is a different and more useful standard. Defensibility means you can show an auditor or regulator a documented method, a current snapshot, and an active process for closing the gaps you have identified.
Governance: Who Owns the Inventory
An inventory without ownership decays within a quarter. The fields go stale, new systems are not added, and within a year the document is more misleading than useful. Three roles need to be defined before the inventory goes live.
The inventory owner. A single accountable person — typically a director-level role within the AI governance, GRC, or privacy function — is responsible for the inventory as an instrument. They do not maintain individual records. They maintain the system, the schema, the review cadence, and the metrics.
The system owner per record. Every individual system in the inventory needs a named business owner who is accountable for keeping that record current. When an AI system changes (new version, new data source, expanded use case), the system owner updates the record. Without this assignment, the inventory owner becomes a bottleneck and updates stop happening.
The reviewer. A separate function — often risk, compliance, or internal audit — periodically samples records to verify accuracy. This is the control that prevents drift between what the inventory says and what the systems actually do.
ISO/IEC 42001’s Clause 5 makes leadership accountability explicit: top management must define AI governance roles and ensure the resources exist to operate them. The inventory is one of those resources, and its operating model is the most visible expression of whether that accountability is real or theatrical.
Tooling: Build, Buy, or Spreadsheet
The tooling decision depends on scale and maturity, not on what is fashionable.
For organizations with fewer than 50 AI systems and a clear path to staying under that threshold, a structured spreadsheet or Notion database with rigid schema enforcement is enough. The constraint is not the tool — it is whether the schema is followed and whether updates happen.
For organizations between 50 and 500 AI systems, a dedicated AI governance platform (Credo AI, FairNow, Holistic AI, OneTrust’s AI module, IBM watsonx.governance, and a growing field of competitors) becomes worth the cost. The value is not the inventory itself — it is the integrations: automated discovery from your SSO and procurement systems, risk assessment workflows, evidence collection for audits, and crosswalks to multiple frameworks.
For organizations above 500 systems or with complex regulatory exposure (financial services, healthcare, federal contractors), the question shifts from “do we need a platform” to “which platform integrates with our existing GRC stack.” At this scale, an isolated AI inventory creates more friction than it removes; integration with your wider risk and asset management environment becomes non-negotiable.
A note on AI security posture management (AI-SPM) tools: these are designed for runtime visibility — they detect AI usage by analysing network traffic, browser activity, and API calls in real time. They are valuable as a discovery input, especially for shadow AI, but they are not a substitute for a governance inventory. AI-SPM tells you what is happening. The inventory tells you what is sanctioned, who is accountable, and what the risk classification is.
What Most Teams Get Wrong
Three failure patterns recur across organizations attempting this for the first time.
The first is treating discovery as a one-time project. The procurement scan, the SSO pull, the repository grep — these get run once, the inventory is published, and then nothing refreshes it. Within six months, the document is wrong. The fix is to convert each discovery method into a recurring control, run quarterly at minimum, monthly for the higher-velocity sources like procurement and SSO.
The second is over-engineering the schema before the inventory exists. Teams spend weeks debating whether to capture 47 metadata fields or 62, then run out of energy before any system is actually catalogued. The pragmatic move is to start with the schema in this guide, populate it for every known system, and add fields only when you can articulate the specific governance decision the new field will support.
The third is building the inventory in isolation from procurement. If new AI systems can enter the organization without the inventory being updated at the point of purchase, you are running a treadmill. The discovery sprint becomes an annual ritual rather than the foundation of an operating control. The integration that matters most is the procurement intake form: a mandatory AI screening question that routes new requests to the inventory owner before a contract is signed.
How AI Inventory Connects to the Rest of Your Governance Program
The inventory is foundational, but it is not the program. It feeds five downstream activities, each of which depends on it.
Risk assessment. Every system in the inventory triggers a risk assessment proportionate to its tier. Without the inventory, the risk register is incomplete by construction.
Vendor due diligence. Third-party AI introduces risk that is invisible to the inventory of internally-built systems. Each external AI vendor in the inventory becomes an entry in your third-party risk management process.
Incident response. When something goes wrong with an AI system — a hallucination causes a customer-facing error, a model produces a discriminatory output, a data leak occurs through a prompt — the inventory is the first artefact responders consult. It tells them what the system does, who owns it, what data it touches, and what controls were supposed to be in place.
Regulatory reporting. EU AI Act conformity assessments, NIST AI RMF profile reporting, and Colorado AI Act algorithmic impact assessments all require system-level documentation that the inventory provides directly.
Decommissioning. When a system is retired, the inventory becomes the audit trail proving the decommissioning happened, what data was archived or deleted, and what dependencies needed to be unwound. NIST AI RMF Govern 1.7 specifically calls out decommissioning processes as a governance requirement, and the inventory is the system of record for that activity.
The inventory is upstream of all of this. Investments downstream — risk frameworks, governance committees, vendor questionnaires produce thinner returns when the inventory beneath them is incomplete.
Frequently Asked Questions
1. How long does it take to build an AI inventory from scratch?
A defensible first-pass inventory takes 14 to 30 days using the sprint approach above for an organization under 1,000 employees, scaling to 60 to 90 days for larger enterprises. Reaching maturity — meaning complete coverage, embedded ownership, and integrated procurement controls — typically takes 6 to 12 months of sustained effort.
2. What counts as an “AI system” for inventory purposes?
Use the ISO/IEC 22989 definition as your reference: an engineered system that generates outputs such as content, predictions, recommendations, or decisions for a given set of objectives, using AI techniques. In practice, this includes generative AI tools, machine learning models, recommendation engines, computer vision systems, and AI features embedded in SaaS products. Rule-based automation that does not learn from data sits outside the definition.
3. Do we need to inventory consumer AI tools employees use on personal devices?
Yes, if they are used for work tasks involving company data. Shadow AI on personal accounts is one of the highest-risk categories precisely because corporate controls do not apply. The inventory should record the existence of the use, the data exposed, and either bring it into a sanctioned tool or formally prohibit it. Ignoring it creates the worst of both worlds: regulatory exposure without operational visibility.
4. How does an AI inventory relate to a data inventory?
They are adjacent and should reference each other but should not be merged. The data inventory catalogues data assets and their classification. The AI inventory catalogues systems that consume and produce data, including which data classes flow through each system. The link between them — which AI system processes which data assets is where most useful governance questions get answered.
5. What is the difference between an AI inventory and an AI registry?
The terms are often used interchangeably, but a useful distinction has emerged: “registry” is increasingly used for the public or regulator-facing record (such as the EU AI Act’s planned high-risk AI database), while “inventory” refers to the internal operational record. Your inventory feeds your registry submissions; the inventory holds more detail than the registry exposes.
6. Can we use AI to build the AI inventory?
Yes, and most mature programs do automated discovery, classification, and metadata extraction are core capabilities of dedicated AI governance platforms. But the inventory itself remains a human-accountable artefact. AI accelerates discovery and reduces manual data entry; it does not replace the named ownership, risk classification, and review cadence that make the inventory defensible.
Closing: Imperfect Beats Absent
The organizations doing AI governance well in 2026 are not the ones who waited until they could build a perfect inventory. They are the ones who started, published a partial first version, and treated the gap list as a roadmap rather than a failure. Regulators, auditors, and insurers are converging on the same expectation: a maintained, named, risk-classified record of every AI system you operate or rely on. The bar is not perfection. The bar is demonstrable progress against a credible method.
Start with the 14-day sprint. Publish what you find. Fix the gaps in the open. The inventory you build in the next month will be more valuable than the one you keep planning to build next quarter.
If your team is preparing for ISO/IEC 42001 certification or building the governance foundation that the inventory anchors, the GAICC ISO/IEC 42001 Lead Implementer training walks through the full management system, including how the inventory connects to risk assessment, controls, and audit readiness.