In August 2023, a tutoring company paid $365,000 to settle the first US federal AI discrimination case after its hiring algorithm automatically rejected female applicants over 55 and male applicants over 60, according to the EEOC’s announcement of the iTutorGroup consent decree. The same software pattern, deployed today, would also fall under New York City’s annual bias audit law, Colorado’s incoming AI Act, and the EU AI Act’s testing obligations for high-risk systems. AI bias has moved from an ethics conversation to a documented compliance risk with named regulators, defined methodologies, and enforceable penalties. This guide covers how to detect, test, and mitigate AI bias in a way that holds up to that scrutiny.
What AI bias risk actually is (and where it comes from)
AI bias risk is the probability that a machine learning model will produce systematically different outcomes for different groups of people, in ways that cause harm or violate law. It is one risk inside a larger AI risk picture, sitting alongside accuracy degradation, security vulnerabilities, and explainability failures. NIST Special Publication 1270 organises AI bias into three buckets that every model owner should know.
Three categories of bias every model owner should know
Systemic bias comes from procedures and practices that disadvantage certain groups before the model is built. A loan approval model trained on historical lending data inherits the redlining patterns inside that data, even if no human at the bank intends it. The model is not making a new discriminatory decision; it is reproducing an old one at scale.
Statistical and computational bias comes from how data is sampled, labelled, or processed. Sampling bias appears when training data underrepresents a population (most facial recognition error rates on darker-skinned faces trace to this). Measurement bias appears when the proxy you measure does not equal the thing you care about (using arrest records as a proxy for crime overweights communities that are policed more heavily). Aggregation bias appears when one model is forced to serve subgroups that should be modelled separately.
Human-cognitive bias enters through the choices designers and operators make: which features to include, what counts as a positive label, when to override the model. None of these biases require malicious intent. They typically arrive through silence, defaults, and convenience.
Why bias is a compliance risk, not just a reputational one
US enforcement bodies have made the legal exposure explicit. The EEOC, CFPB, DOJ, and FTC issued a joint statement in April 2023 confirming that existing antidiscrimination, consumer protection, and credit laws apply to automated systems. A biased model is not a separate problem; it is the same Title VII, ADEA, ECOA, or Fair Housing problem with a different cause. That framing is what changes the conversation in compliance committees.
Detecting AI bias: where to look and what to look for
Detection is the work of finding bias before it produces a regulator letter. It begins with two questions: which attributes are protected for this use case, and what are the proxies for those attributes inside your data?
Protected attributes and the proxy variable problem
In a US employment context, federal protected attributes include race, colour, religion, sex (including pregnancy, sexual orientation, and gender identity), national origin, age (40 and over), disability, and genetic information. State and local laws extend the list. The textbook example of a proxy is a US ZIP code, which can serve as a near-perfect predictor of race in many metropolitan areas. Removing race from a model and keeping ZIP code does not remove the bias; it just hides it. Real proxy detection requires statistical analysis: look for any non-protected feature whose distribution differs sharply across protected subgroups, then test whether removing it changes the model’s disparate behaviour.
| Protected attribute (US) | Common proxies | Where to check |
| Race / ethnicity | ZIP code, surname, first name, school attended, language spoken at home | Hiring, lending, housing, healthcare |
| Sex / gender | First name, prior employers, job titles, gaps in employment | Hiring, promotion, performance scoring |
| Age (40+) | Graduation year, length of work history, technology proficiency tests | Hiring, layoff selection, training selection |
| Disability | Voice biometrics, typing cadence, video interview body language scoring | Video interviewing, productivity monitoring |
Subgroup performance analysis: the workhorse technique
The single most useful detection technique is also the most basic: slice your model’s performance metrics by protected subgroup and compare. If your fraud model has a 2% false positive rate overall but a 9% false positive rate for one demographic group, that is a finding regardless of what the algorithm intended. This is the foundation of every fairness audit, and it is the test that NYC Local Law 144 essentially codifies for hiring tools.
Slice analysis only works if you have, or can responsibly infer, the demographic data. In jurisdictions and contexts where you cannot collect protected attributes directly, methods such as Bayesian Improved Surname Geocoding (BISG) for race, or self-identification surveys, are accepted approaches. The point is that you cannot test for bias against groups you refuse to count.
When to do an AI impact assessment
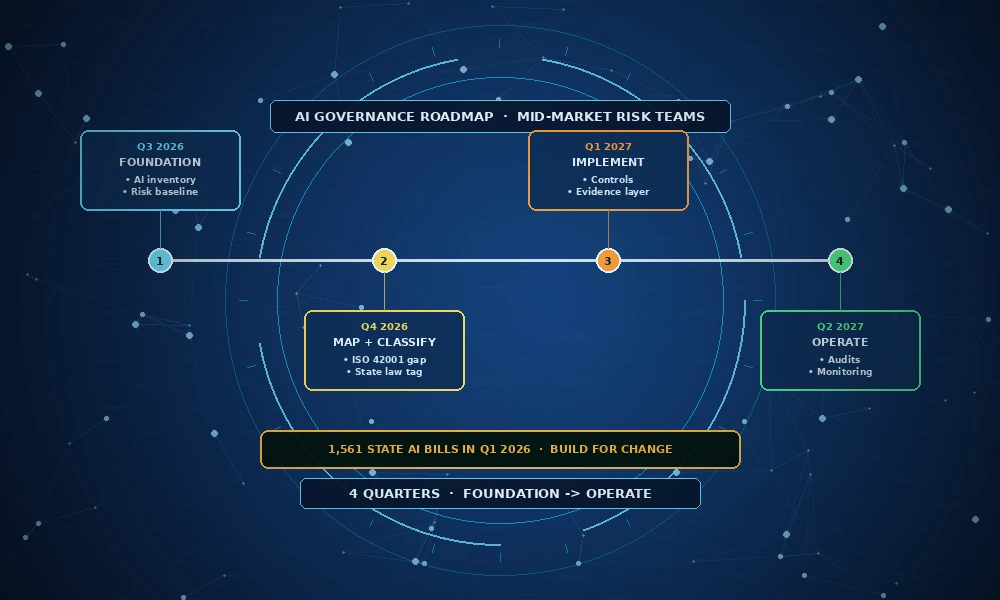
An AI impact assessment is the structured pre-deployment review that turns detection from an ad-hoc scramble into a programme. It documents the system’s purpose, the populations affected, the foreseeable harms, the data sources and known limitations, and the controls applied. The Colorado AI Act and the EU AI Act both require some version of this for high-risk systems, and ISO/IEC 42001 control A.6.2.4 names AI system impact assessment as a baseline expectation. If you only do bias detection in one place in your AI lifecycle, this is the place.
Testing AI for bias: choosing and applying fairness metrics
Most published guides on AI bias hand the reader a list of fairness metrics and stop there. The harder problem is choosing the right one. There is no neutral default. Metrics encode different ideas of what fairness means, and several of them are mathematically incompatible with each other when group base rates differ. Picking the wrong one for your use case produces false confidence.
The four metrics that cover most use cases
Demographic parity (also called statistical parity) asks whether the rate of positive outcomes is equal across groups. Selection rate for Group A divided by selection rate for Group B should be close to 1. This is the metric behind the EEOC’s four-fifths rule: a ratio below 0.80 is treated as evidence of adverse impact in US employment law. NYC Local Law 144 effectively codifies the four-fifths logic for AEDTs.
Equal opportunity asks whether the true positive rate is equal across groups, given the actual outcome. If a loan model approves qualified applicants at 80% in one group and 50% in another, that is an equal opportunity failure even if overall approval rates look balanced.
Equalised odds is the stricter version: both true positive rate and false positive rate must be equal across groups. This matters most where false positives carry serious harm (criminal justice, fraud detection, content moderation flagging).
Calibration asks whether a model’s predicted probabilities mean the same thing across groups. A 70% risk score should correspond to a 70% real-world rate, regardless of group. This is the metric most relevant to risk scoring (credit, insurance, recidivism).
A decision framework for picking the right fairness metric
| Use case type | Primary metric | Why |
| US hiring (AEDT under LL 144 or Title VII) | Demographic parity / impact ratio (4/5 rule) | This is the legal standard regulators apply. |
| Credit / lending decisions | Equal opportunity + calibration | Both ECOA disparate treatment and risk score reliability matter. |
| Fraud detection / content moderation | Equalised odds | False positives cause direct harm; both error types must be balanced. |
| Healthcare risk scoring | Calibration (with clinical review) | Predicted risk must reflect true risk for treatment decisions. |
| Generative AI outputs | Subgroup quality + counterfactual testing | Standard metrics break down; red-team for representational harm. |
One uncomfortable mathematical fact: when the underlying base rate of the outcome differs between groups, you cannot satisfy demographic parity, equalised odds, and calibration simultaneously. This is the impossibility theorem in fairness machine learning. Choosing a metric is therefore choosing a value: which kind of unfairness are you least willing to accept? That decision belongs in the AI impact assessment, signed off by the business owner, not buried in a data scientist’s notebook.
Tools that make fairness testing operational
Three open-source toolkits handle most testing needs. IBM AI Fairness 360 (AIF360) offers the broadest metric coverage and built-in mitigation algorithms. Microsoft Fairlearn is more streamlined and integrates cleanly with scikit-learn workflows. Aequitas from the University of Chicago focuses on audit-style reporting and is often used by independent auditors. None of these tools choose the metric for you, and none generate audit-ready evidence on their own; that work still belongs to the governance layer.
Mitigating AI bias: pre-processing, in-processing, and post-processing
Mitigation techniques fall into three families based on where in the model lifecycle they intervene. The right choice depends on what you can change, what trade-offs you can absorb, and, increasingly, what is legal in your jurisdiction.
Pre-processing: fix the data
Pre-processing techniques modify the training data before the model sees it. Reweighing assigns different importance weights to underrepresented or unfavourably labelled groups so the model learns from a more balanced sample. Resampling does the same thing more bluntly through over- or under-sampling. Synthetic data augmentation generates new training examples for underrepresented groups, increasingly using generative models, though this introduces its own risks if the synthetic data inherits the original bias. Pre-processing is the most common starting point because it leaves the downstream model architecture untouched.
In-processing: fix the model
In-processing techniques bake fairness constraints into the training process itself. Adversarial debiasing trains a second network to predict the protected attribute from the main model’s output, and penalises the main model when the adversary succeeds. Fairness-constrained optimisation adds a fairness term to the loss function so the model is jointly minimising error and unfairness. These methods often produce the cleanest fairness improvements but require model access and retraining, which is not always possible (especially with third-party or foundation models).
Post-processing: fix the outputs (and its legal landmine)
Post-processing techniques adjust the model’s outputs after prediction. Threshold optimisation sets different decision thresholds per group so that fairness metrics are equalised. Calibration adjustment modifies predicted probabilities. Post-processing is the easiest to deploy because it does not touch the model. It is also the technique most likely to create legal exposure in US employment and lending contexts, because explicitly using race or sex as an input to set different thresholds can constitute disparate treatment under Title VII or ECOA, even if the intent is to reduce disparate impact. The Supreme Court’s Students for Fair Admissions decision sharpened the legal scrutiny on group-conscious decision rules. Talk to counsel before applying post-processing to a model used for employment, credit, housing, or education decisions in the United States.
| Family | Effort | Effect | Trade-off |
| Pre-processing | Low–Medium | Moderate | Lower data fidelity |
| In-processing | High (needs retraining) | Strong | Possible accuracy hit |
| Post-processing | Low | Strong on metric | Legal exposure (US) |
In practice, mature programmes stack these. They start with data improvements, apply in-processing during retraining where feasible, and use post-processing only as a defensible last resort with documented legal review.
The regulatory picture: what US and global AI bias laws actually require
AI bias is regulated in the United States through a mix of pre-existing antidiscrimination law, sector regulators, and a fast-growing patchwork of state and city statutes. Outside the US, the EU AI Act now sets the most prescriptive global benchmark.
United States: a patchwork that is getting denser
NYC Local Law 144 took effect on July 5, 2023 and remains the only enforced US bias-audit mandate. It requires employers using automated employment decision tools (AEDTs) to commission an annual bias audit by an independent auditor, publish the results, and notify candidates at least 10 business days before use. Penalties run from $500 per first violation up to $1,500 per day. A December 2025 New York State Comptroller audit found enforcement weaker than expected (75% of complaints to the city’s hotline were misrouted), but also signalled that DCWP will tighten enforcement, including more rigorous investigations.
Colorado SB 24-205 (the Colorado AI Act) is the first comprehensive US state AI law. After amendment, it now takes effect on June 30, 2026. It imposes a duty of reasonable care on developers and deployers of high-risk AI systems to protect consumers from algorithmic discrimination, requires impact assessments and a formal risk management policy, and creates an affirmative defence for organisations that can show compliance with a recognised framework such as NIST AI RMF or ISO/IEC 42001.
EEOC enforcement applies federal antidiscrimination law (Title VII, ADEA, ADA) to AI-driven employment decisions. The EEOC’s May 2023 technical assistance document on Title VII and AI makes clear that the four-fifths rule remains the analytical baseline and that an employer is responsible for adverse impact created by a vendor tool. Sector regulators (CFPB on credit, HUD on housing, FTC on consumer protection) have issued parallel guidance.
European Union: the AI Act’s bias requirements
The EU AI Act’s bias-relevant obligations sit primarily in two articles. Article 10 requires that high-risk AI systems be developed using training, validation, and testing datasets that meet quality criteria, including examination for possible biases that could affect health, safety, or fundamental rights. Article 15 requires that high-risk systems achieve appropriate levels of accuracy, robustness, and cybersecurity throughout their lifecycle, with metrics declared in the technical documentation. High-risk obligations apply from August 2, 2026. The Act applies extraterritorially: a US company providing a high-risk AI system into the EU market is in scope.
What ‘bias audit’ actually means under each regime
| Jurisdiction | Instrument | Scope | Audit type | Effective |
| New York City | Local Law 144 | Hiring AEDTs | Annual independent bias audit + public summary | July 2023 |
| Colorado | SB 24-205 | High-risk AI in consequential decisions | Risk mgmt policy + annual impact assessment | June 2026 |
| US federal | Title VII / ADEA / ECOA + EEOC guidance | Employment, credit, housing | Disparate impact testing (4/5 rule) | In force |
| Illinois | AI Video Interview Act | Video interviewing AI | Notice + demographic reporting | In force |
| EU | AI Act Art. 10, 15 | High-risk AI systems | Data governance + accuracy/robustness testing | Aug 2026 |
Governing bias risk under recognised frameworks: NIST AI RMF and ISO 42001
Regulators increasingly point to the same two frameworks when describing what good looks like. Both Colorado SB 24-205 and the EU AI Act’s harmonised standards work explicitly recognise NIST AI RMF and ISO/IEC 42001 as defensible bases for compliance. Treating them as paperwork is a missed opportunity; treating them as the operational backbone of a bias programme is what regulators are actually rewarding.
Mapping bias controls to NIST AI RMF subcategories
The NIST AI Risk Management Framework 1.0 published in January 2023 organises AI risk work into four functions: GOVERN, MAP, MEASURE, and MANAGE. Bias work touches all four, but two subcategories carry most of the load. MEASURE 2.11 calls for fairness and bias to be evaluated and results documented. MAP 1.1 requires the context of AI system use to be understood, including affected populations. GOVERN 1.5 names the policies and procedures for bias risk. Mapping each section of an internal bias playbook to these subcategories turns the framework from a reference document into an operating model.
How ISO 42001 turns bias work into a managed system
ISO/IEC 42001:2023 is the international management system standard for AI. Its Annex A controls include several that bear directly on bias: A.6.2.4 (AI system impact assessment), A.7.4 (quality of data for AI systems), A.8.2 (system-related processes for assessing AI risks), and A.9.3 (objectives for responsible use of the AI system). The advantage of ISO 42001 over a control-by-control checklist is that it forces a closed loop: policy, objective, control, monitoring, audit, improvement. That loop is exactly what auditors and regulators look for when they ask whether an organisation ‘has’ a bias programme rather than whether it has run a one-off test.
Govern365.ai’s AI model registry maps each system to its applicable ISO 42001 clauses and NIST AI RMF subcategories, including bias controls (A.6.2.4, MEASURE 2.11), so the framework view is generated automatically rather than maintained in spreadsheets.
From one-off testing to continuous bias governance
Most organisations test for bias once before a model launches and then move on. That is where bias programmes most often fail. Models drift, populations drift, and what was fair last quarter is not necessarily fair this quarter.
Why bias drifts even when models do not change
Even a frozen model produces different outcomes as the population it scores changes. A credit model trained on a pre-pandemic borrower base will behave differently against a post-pandemic borrower base, with subgroup effects that may not appear in aggregate accuracy metrics. Concept drift (the relationship between features and outcome shifts) and population drift (the input distribution shifts) both affect bias metrics independently of the model. Continuous monitoring is the only way to detect this before it produces a complaint or an audit finding.
Monitoring cadence should follow risk tier. High-risk systems (employment, credit, healthcare, housing) need real-time or weekly fairness metric tracking with automated alerts. Moderate-risk systems can run monthly or quarterly. Low-risk systems still need at least an annual review and a trigger for re-test on any material change to the model, the data pipeline, or the population served.
The evidence layer: what auditors actually want to see
The single most common failure mode in mature bias programmes is the evidence layer. Teams run the right tests and apply the right mitigations, but cannot reconstruct, six months later, what was tested, on what data, by whom, with what result, and what was decided. When an EEOC investigator, an EU notified body, or a Colorado AG inquiry arrives, screenshots from a notebook do not constitute defensible evidence.
A defensible evidence layer typically includes: a model card or equivalent documenting purpose, training data, performance, and known limitations; the AI impact assessment with sign-offs; the fairness test results with metric definitions and dataset versions; the mitigation actions and the rationale for the chosen approach; the monitoring records over time; and the change log linking model versions to retest dates. This is the layer that turns a bias programme from theatre into assurance.
Govern365.ai’s compliance dashboards aggregate fairness metric drift, mitigation history, and audit evidence in a single view tied to each model in the registry, so the evidence is generated as a by-product of the work rather than reconstructed under deadline.
Frequently asked questions
What is AI bias risk?
AI bias risk is the probability that a machine learning model produces systematically different outcomes for different groups in ways that cause harm or violate antidiscrimination law. NIST SP 1270 categorises its sources as systemic, statistical/computational, and human-cognitive. It is treated as a managed compliance risk under frameworks including NIST AI RMF and ISO/IEC 42001, not as an ethics question alone.
How do you detect bias in an AI model?
Detection combines three techniques: identifying protected attributes and their proxies in the data, conducting subgroup performance analysis to compare metrics across groups, and running an AI impact assessment before deployment. For high-risk systems, detection continues post-deployment through ongoing fairness monitoring, since both the model and the population it scores can drift over time.
What is the four-fifths rule in AI bias testing?
The four-fifths rule is the EEOC’s analytical standard for adverse impact. If the selection rate for one protected group divided by the selection rate for the most-selected group falls below 0.80, the result is treated as evidence of disparate impact. NYC Local Law 144 effectively codifies this for hiring AEDTs. The rule is a screening threshold, not a safe harbour: statistically significant smaller disparities can still violate the law.
Which fairness metric should I use?
It depends on the use case and the type of harm. Demographic parity (and the four-fifths rule) governs US hiring. Equal opportunity and calibration matter for credit decisions. Equalised odds matters where false positives cause direct harm, such as fraud detection or content moderation. The choice should be documented in an AI impact assessment, because mathematically you cannot satisfy all fairness definitions simultaneously when group base rates differ.
Is the NYC AI bias audit mandatory?
Yes. NYC Local Law 144 has been in force since July 5, 2023. Employers and employment agencies using an automated employment decision tool to evaluate candidates or employees in NYC must commission an annual independent bias audit, publish a summary on the company website, and notify candidates 10 business days before use. Penalties run from $500 to $1,500 per violation per day, and enforcement is expected to tighten following a December 2025 NY State Comptroller review.
How does ISO 42001 address AI bias?
ISO/IEC 42001:2023 addresses bias through several Annex A controls: A.6.2.4 requires an AI system impact assessment, A.7.4 covers quality of data for AI systems, and the broader management system requirements (Clauses 6, 8, 9) drive bias work into a closed loop of policy, control, monitoring, and improvement. Achieving certification provides defensible third-party assurance, which both Colorado SB 24-205 and EU AI Act conformity work treat as evidence of reasonable care.
Closing the loop on AI bias risk
AI bias risk is no longer a question of whether to act; the EEOC, NYC DCWP, the Colorado AG, and the EU all now have named methods, named penalties, and (in some cases) named defendants. The organisations that handle this well share a pattern: they treat bias as a managed risk rather than a one-off check, they choose fairness metrics deliberately for each use case, they document their decisions, and they monitor models in production rather than at launch.
A practical first step: build (or refresh) an inventory of every AI system in use, tagged by risk tier and protected-attribute exposure. From that inventory, fairness metric selection, monitoring cadence, and audit-evidence requirements all become decisions with defensible answers.Govern365.ai, by the Global AI Certification Council, gives compliance and AI governance teams the model registry, fairness monitoring, and audit-evidence layer to do this work in one place. Start your 14-day free trial and run your first AI system through a NIST AI RMF and ISO 42001 mapped review.